AI Agent 基础设施
- 1: 基础设施介绍
- 2: 环境
- 2.1: 沙箱
- 2.1.1: E2B
- 2.1.1.1: 介绍
- 2.1.1.2: 文章
- 2.1.1.3: 实践
- 2.1.1.3.1: 快速开始
- 2.1.1.3.2: 连接大模型
- 2.1.1.3.2.1: OpenAI
- 2.1.1.3.3: 上传文件
- 2.1.1.3.4: 安装自定义包
- 2.1.1.3.5: 用 AI 分析数据
- 2.1.1.4: 源码
- 2.1.1.4.1: e2b仓库
- 2.1.1.4.2: code-interpreter仓库
- 2.1.1.4.3: infra仓库
- 2.1.2: Modal
- 2.1.2.1: 介绍
- 2.1.3: microsandbox
- 2.1.4: 总结
- 2.2: 浏览器
- 3: 上下文
- 4: 工具
1 - 基础设施介绍
1.1 - 基础设施概述
背景
2025 年以来,Agent 开发量和使用量都有明显提高。Agent 的爆发带来了 Agent Infra 需求的爆发。在过去 1-2 年,Agent 开发大多依赖开发者手动使用传统 Infra 搭建,开发工程量大、流程复杂,但随着越来越多 Agent-native Infra 涌现,Agent 开发的难度和周期都在缩小,开发的范式正在重构和收敛。
目前 Agent Infra 是模型公司、云厂商、初创公司都在积极拓展的领域.
分类
Environment 指的是 Agent 可操作的容器,相当于给了 Agent 一台可自行操作的计算机,Agent 可以在其中端到端地完成任务,这个赛道包括 Sandbox、Browser Infra、Agent 操作系统等不同的细分领域,我们看好其中的 Sandbox 和 Browser Infra。
Context 为 Agent 有效运行提供所需的信息,这个信息既包括任务相关的背景知识,也包含各类工具的使用方法。有了这些信息,Agent 才能在特定任务场景中,合理判断应以哪种顺序调用哪些工具,才能更有效地完成任务。我们将主要分析这个赛道中的 RAG、MCP 和 Memory。
Tools 相关的 Infra 使 Agent 能够便捷调用各类工具,实现搜索、UI 设计、数据访问、支付等多样化的任务。随着 Agent 交互复杂度的持续上升,工具层正迅速扩展。搜索(Search & Scraping)、金融(Finance & Payment)、后端工作流(Backend Workflow)这三类工具,尤为值得重点关注。
Security Infra 以 Agent-native 的方式保障 Agent 的行为与数据在执行过程中的安全与合规。随着 Agent 能力边界的不断拓展,市场对 Agent 安全性的要求也在同步提高。然而,这一环节的 AI-native Infra 机会需要在 Agent 生态更为完善后才能出现更清晰的格局。
备注: 这个分类来自文章 https://www.bestblogs.dev/article/234f9a
1.2 - 信息收集
社区的资料收集
社区已经有一些ai agent 基础设施的资料收集工作,可以经常从这些地方获取到新的信息:
2 - 环境
Environment 指的是 Agent 可操作的容器,相当于给了 Agent 一台可自行操作的计算机,Agent 可以在其中端到端地完成任务,这个赛道包括 Sandbox、Browser Infra、Agent 操作系统等不同的细分领域.
2.1 - 沙箱
2.1.1 - E2B
2.1.1.1 - 介绍
介绍
RUN AI-GENERATED code SECURELY in your APP.
在您的应用程序中安全地运行 AI 生成的代码。
E2B is an open-source runtime for executing AI-generated code in secure cloud sandboxes. Made for agentic & AI use cases.
E2B 是一个开源的运行时,用于在安全云沙箱中执行 AI 生成的代码。适用于代理和 AI 用例。
官网
-
官网: https://e2b.dev/
-
cookbook: https://e2b.dev/cookbook/
用户案例
Build for AI Use Cases
-
AI 数据分析:
从运行短的 AI 生成的代码片段,到完全自主的 AI 代理。
-
AI 数据可视化:
运行 AI 生成的代码来渲染图表和基于您数据的视觉输出。
-
Coding Agents:
使用沙盒执行代码,使用 I/O,访问互联网,或启动终端命令。
-
Generative UI:
使用沙盒作为代码运行时,为 AI 生成的应用程序提供支持。支持任何语言和框架。
-
Codegen Evals:
使用沙盒作为您的 codegen 健身房,用于流行的评估,如 swe-benchmark 或内部评估。
-
Computer Use:
使用桌面沙盒为您的 LLM 提供安全的虚拟计算机。
-
Deep Research Agents:
让您的代理在沙盒环境中完成复杂任务。
2.1.1.2 - 文章
2.1.1.2.1 - Manus 背后的重要 Infra,E2B 如何给 AI Agents 配备“专属电脑”?
原文: https://www.woshipm.com/ai/6215249.html
在AI技术飞速发展的当下,多智能体系统(Multi-Agent System)正成为新的突破方向,而Agent Infra(智能体基础设施)则成为实现这些系统落地的关键。E2B作为这一领域的新兴参与者,凭借其为Manus等项目提供的“专属电脑”支持而备受关注。E2B不仅允许用户在云端的安全隔离沙盒中运行AI生成的代码,还致力于成为AI Agent时代的AWS,为Agent从开发到部署的完整生命周期提供支持。
Multi agent 系统正成为新的突破方向的过程中,agent infra 也成为落地关键。在 computer use 带来范式创新的趋势下,virtual machine 将成为潜在创业机会,E2B 就是这个领域的新兴参与者。
E2B 之所以受到市场关注很大程度上是因为 Manus,Manus agent 完成任务过程中的 virtual computer 支持正是来自于 E2B。E2B 成立于 2023 年,作为一个开源基础设施,允许用户在云端的安全隔离沙盒中运行 AI 生成的代码。E2B 本质上是一个可以快速启动(~150 毫秒)的 microVM,它的底层类似于 AWS Firecracker 这个代表性的 MicroVM,在此基础上, AI Agents 可以在 E2B 中运行代码语言、使用浏览器、调用各种操作系统中的工具。
随着 Agent 生态的繁荣,E2B 的沙盒月创建量一年内从 4 万增长到 1500 万,一年内增长了 375 倍。
为什么 AI agents 需要专属的“电脑”?
为了更好地理解这个问题,我们编译了 CEO Vasek Mlejnsky 最新的两次访谈,以及 E2B 内部一篇有关 computer use agent 的技术博客。本文详细介绍了 E2B 的技术理念,以及团队从代码解释器转型为更通用的 agent 运行环境背后的思考。
E2B 的愿景很大,CEO 的目标是成为 AI Agent 时代的 AWS,成为一个自动化的 infra 平台,未来可以提供 GPU 支持,满足更复杂的数据分析、小模型训练、游戏生成等需求,并可以托管 agent 构建的应用,覆盖 agent 从开发到部署的完整生命周期。

01.E2B 是什么?
E2B 的创立、发展和转型
E2B 的两个创始人是 Vasek Mlejnsky(CEO)和 Tomas Valenta(CTO),来自捷克。在正式创业之前,二人就已经合作过很多项目。
在创立 E2B 之前,Vasek 和 Tomas 在做的产品叫做 DevBook,这是一个面向开发者的交互式文档,可以看作是 E2B 的雏形。GPT-3.5 发布后,二人尝试构建 agent 来自动化工作,因为每一个项目都需要一套工具集成到后端,于是他们利用 DevBook 已有的沙盒技术运行代码,并将 agent 自动拉取 GitHub、编写代码、部署到 Railway 的相关内容发到了 twitter,推文意外被 Greg Brockman 等人转发,在几天内获得了大约 50 万次浏览。之后二人迅速开源并将重心转向沙盒环境,在 2023 年 3 月创立了 E2B。

Vasek 表示,团队一开始就意识到了代码执行是 agent 技术栈中至关重要的一环。代码就像是一种通用语言,可以作为连接一切的粘合剂,人类开发者就是通过代码把各种服务和 API 连接起来,从而让系统跑得起来的,为什么 agent 不能做同样的事情呢?Agent 需要一个安全、灵活的代码执行环境,且随着 agent 越来越强大,代码运行环境也变得越来越重要。
E2B 发展的一个关键点是引入了“代码解释(code interpretor)”这个概念,当团队开始用这个词解释产品的时候,很多用户一下子就明白了:如果用户想用 AI 进行数据分析、可视化,代码执行就非常关键,因为这些任务都需要运行 AI 生成的代码;如果想让大模型更聪明,比如能做数学运算,那代码就可以被看作是一个非常通用的计算器;有用户想构建一个 AI 驱动的 Excel,只需要描述每一列该做什么,agent 就会根据描述动态生成代码、执行代码,用户就可以轻松完成数据增强、数据分析等任务。
在创业早期,E2B 花了很多时间通过使用明确的用例来教育市场、获取用户。
2024 年 10 月,Anthropic 推出了 computer use,但其实早在六个月前,E2B 就已经有了一个桌面版的沙盒环境,只是当时没有模型能够真正用起来,因此这一功能未被广泛关注。大约在 2024 年底至 2025 年初,团队开始观察到用户将沙盒用于 computer use。同时 Vasek 注意到,在 2024 年的时候人们还在尝试构建 agent,但到了 2025 年,agent 已经被越来越多地被投入到生产环境,出现了大量新的用例。

如何定义B端产品及B端产品经理方法论
相较于C端产品,B端产品最大的特点是:面向特定领域用户,且数量少得多,但更注重对用户专业领域操作流程的深度挖掘——也就是专业性更强,与业务的结合更紧密。
查看详情 >
随着这一趋势的发展,人们已经不再沙盒仅仅用于运行数据分析等代码片段,E2B 顺势调整了产品定位,不再将沙盒仅视为代码解释器,而是逐渐拓展为更通用的 LLM 或者 agent 运行时的环境。
受益于 LLM 能力的提升和 agent 的落地,E2B 在 2024 年取得了非常好的增长,2025 年更是直线上升,沙盒的月创建量一年内从 4 万增长到 1500 万。
产品功能和定位
E2B 提供了一个安全的沙盒环境,能够让 AI agent 在云端安全运行 ,agent 可以使用沙盒创建文件、使用浏览器、分析数据、编写小型应用程序、创建 Excel 表格等,可以实现的任务场景相当丰富。
E2B 支持多种代码语言,目前使用最多的是 Python 和 JavaScript,前者每月有接近 50 万次的 SDK 下载,后者有约 25 万次。

Vasek 希望 E2B 能成为 AI agent 时代的 AWS,成为一个自动化的 infra 平台,未来可以提供 GPU 支持,满足更复杂的数据分析、小模型训练、游戏生成等需求,并可以托管 agent 构建的应用,覆盖 agent 从开发到部署的完整生命周期。
但这并不意味着 E2B 会去做 prompt 或者 memory 等,Vasek 相信 LLMs 会持续变得更强大,很多现在看起来复杂的问题,未来可能都会自动被解决。
但有些问题是比较难被自动解决的:比如怎么确保总是能从 LLM 得到一个响应?如果接入的模型提供商宕机了,要怎么自动切换到另一个提供商?这是开发者多年来一直在面对的老问题,只不过现在换了场景:以前是在传统软件中,现在是在 AI 环境中。
此外,传统云计算是为已有应用设计的,而 agent 执行的代码是动态生成、不可预知的。这些问题还是需要用一种全新的方式来解决。
Vasek 提到,大多数时候,开发者找到 E2B 也是从一个很简单的需求开始的,比如开发者一开始只是用一个 serverless 函数,或者是在服务器上跑一个 API 接口来执行代码,在开发的早期阶段甚至可以就在本地运行代码。
但随着产品的发展,尤其是想要规模化地运营时,问题就会一个接一个地出现了。比如:
- 安全性与隔离性:开发者希望确保不同用户的代码不会在同一个环境里运行,因为开发者并不知道用户的代码具体在干什么,也不知道有没有敏感信息被泄露。
- 权限与自由度:开发者想给 agent 或 AI 应用尽可能大的自由度,让它们可以运行任何想运行的代码,这可能包括访问完整的文件系统、下载依赖包等。
这些都会带来各种技术和安全挑战,比如如何高效、动态地生成隔离的代码执行环境,如何让这些环境随时可用,并确保稳定和安全等等。很多开发者慢慢意识到这需要一个更专业、更安全的解决方案,也就自然而然地转向像 E2B 这样的产品。
随着 multi agent 的发展,团队接下来会尽快推出新功能 forking(分叉)和 checkpointing(检查点),从而使得多个 agent 可以并行尝试不同解决路径,就像树状结构,每个节点就是一个沙盒快照,可以分叉出去进入下一个状态,最终找到最优路径,类似蒙特卡洛树搜索。forking 和 checkpointing 还可以很好地解决本地状态管理问题,比如保留中间进度,避免每次都从头来过。

蒙特卡洛树搜索是一种常用于决策问题中的搜索算法,结合了随机模拟和树状搜索的优点,能在计算资源有限的情况下找到接近最优的决策。
E2B 目前已经实现了 persistence(持久化),这是实现 forking 和 checkpointing 的基础。用户可以先暂停沙盒,然后在一个月后将沙盒恢复到暂停时的状态,从而使得 agent 可以运行更长时间或间歇性执行任务。
使用场景
E2B 最重要的使用场景之一是给 AI 数据分析提供支持。
开发者上传一个 CSV 文件,然后向 AI 提问:“我上传了一个 CSV 文件,它包含这些列,你可以写 Python 代码来分析这些数据。”但是这些代码必须要有地方可以运行,E2B 专门为这种场景打造了一个高度优化过的运行环境,并提供了一个专用的 SDK,叫做 code interpreter SDK,整个环境的闭环非常自然:
- 开发者可以直接创建图表,甚至是交互式图表;
- 开发者可以安装第三方库,E2B 已经预包装了常用的数据分析包;
- AI 模型可以方便地引用自己前面生成的代码块;
- 如果代码出错了,开发者可以把错误信息快速反馈给 LLM,让它尝试修复。
对于开发者来说,由于 E2B 做了隔离机制,每一个 agent 都有专属的沙盒环境,agent 会更可靠。

E2B 第二大使用场景是作为 AI 生成应用的运行平台,这个领域发展得非常快,尤其是人们开始基于各种不同的框架来构建 AI 驱动的应用,这些应用需要一个可以运行 AI 生成代码的环境,也就是需要一个专门的运行时(runtime)来支撑这类 AI 生成的应用逻辑。
因此 E2B 创建了一个开源模板,叫做 Fragments,开发者可以复制这个模板作为构建自己 AI 应用平台的起点。开发者可以在界面中直接输入:“帮我用 Next.js 构建一个待办事项应用”,LLM 会生成相应的代码,并把它发送到沙盒环境中运行,开发者马上就会看到应用效果。

E2B 现在正在逐步进入更多的场景,Vasek 观察到有开发者在做代码执行的时候,目的并不是构建面向开发者的 agent,比如有开发者做了一个 AI 驱动的 Excel,这个产品并不是面向开发者的,它的最终用户可能是 CEO、企业高管、业务人员,或者公司内部任何需要使用数据的人。但在这个产品底层,是通过代码执行来实现功能的。
Vasek 表示看到了越来越多这样的趋势——虽然现在还非常早期,但这是一个非常令人兴奋的方向,因为人们正在意识到,代码执行不仅仅服务于开发者,也可以服务于其他类型的用户。
还有一个有趣的 use case 是 Hugging Face 在构建 Open R1 的时候,在强化学习、代码生成的训练阶段用到了 E2B,具体来说,Open R1 模型有一个训练步骤是模型接收一个编程题,然后需要生成并在某个地方运行代码,接着奖励函数会返回一个 0 或 1 来表示是否正确,再用这个反馈来优化模型。

Hugging Face 使用 E2B 的沙箱来运行这些代码,每个训练步骤会启动数百甚至上千个沙箱,从而实现高并发。这种方式非常快,而且不需要用昂贵的 GPU 集群来处理。在使用 LLM 的时候,开发者不用担心它会改动集群里的权限进而影响系统,因为每个沙盒都是彼此隔离和安全的。
Vasek 表示已经有几家公司要以这种方式来使用 E2B 训练模型,虽然这不是团队一开始设想的场景,但现在看起来是非常合理的。从 AI agent 生命周期角度来看,E2B 应当在周期里介入得越早越好,而训练阶段可能就是最早的一环。
如何提高开发者粘性?
提升开发者的粘性是构建开发者工具中最难的一点,关键在于找到合适的开发者体验(DX)。
**Vasek 认为,“GPT Wrapper”在当下是个好生意,能够快速利用底层模型能力提升带来的益处,**目前来看,用户切换模型的成本越来越低,基本上只需要一两行代码,就可以从 Gemini 切换到 Claude 或者 OpenAI,用户也经常切换模型。但确保自身的应用或 agent 在模型切换中还能正常运行其实是很难的。
E2B 的一个重要价值主张是,当客户(尤其是大公司)使用 E2B 时,他们不会觉得被某一个 LLM 锁死。比如 OpenAI 有自己的 code interpreter,但很多客户并不想用,一方面是因为他们控制不了,另一方面是如果他们用了,他们就必须一直绑定在 OpenAI 上,没法切换到 Google 或者开源模型,因为 OpenAI 的 code interpreter 不会去适配其他模型,所以他们根本没有这个动力去使用。所以 E2B 需要让开发者更容易去切换模型。
**Vasek 认为真正赢得开发者的方法是提供的体验好到让开发者几乎不需要思考自己在用一个工具——就像是大脑的延伸一样。**虽然这听起来好像反而让人更容易换工具,因为开发者没有在有意识地去依赖它,但实际上,正因为开发者不需要思考,才更不愿意换,工具完全进入了工作流。要达到这个效果,需要注意各种小细节,比如开发者不需要理解 infra 的复杂逻辑,不需要做一堆配置文件,这些东西是糟糕的开发体验。
总而言之,E2B 需要对 LLM 保持中立。从技术角度来看,E2B 希望成为 agent 领域的 Kubernetes,同时具有更好的开发者体验。
Kubernetes 是一个开源的容器编排平台,用于自动化容器化应用的部署、管理、扩展和运行。
02.E2B 是怎么看 AI Agent 的?
Agent 时代,软件该如何定价?
Agent 的定价是一个非常值得讨论的问题,有人认为传统的按席位收费并不适用于 agent,因为有些 agent 可能只运行几秒钟,有些 agent 可能需要运行几个小时,但如果按使用量计费,用户可能会在不知情的情况下花费很多钱,从而导致用户不敢继续使用。
Vasek 认为对于 infra 公司来说,定价确实是一个非常难的事情。
创始人在创办一家 infra 公司时,常常希望把定价做得非常简单,比如每月用户就付一百美元,如果超过了某个限制,再使用其他方式收费,但开始扩展规模的时候,创始人就会发现需要考虑的因素非常多,比如要考虑流量、存储量,还有各种细小的资源消耗等等,最后往往会有一张非常复杂的价格表。
因此如何向用户传达定价逻辑就变得非常重要,基本的功能是必须要有的,比如计费上限、费用预警,这些功能可以确保用户感到对自己的支出是有完全的掌控感。同时还要提供良好的可观测性,用户必须清楚知道他们用掉了什么资源、花了多少钱。
Agent 的下一个应用场景:computer use
现在 agent 被广泛谈论的三个主要使用场景是:
- 写代码(coding),比如 Cursor;
- 销售(sales),比如市场拓展环节开始自动化,很多原本销售代表需要手动做的工作正在被解放;
- 客户支持(customer support),比如 Sierra 和 Decagon 这样的公司正在被《财富》百强企业使用。
Vasek 认为下一个 agent 真正能工作起来的场景是:让 agents 控制电脑或者浏览器。
Anthropic 是去年最早公开发布相关内容的公司之一,OpenAI 今年也发布了 Operator。这件事带来了各种可能性和挑战,比如,用户可能不会希望 agent 完全随意使用自己的电脑,用户还是会希望有一些控制,比如可以选择是否允许 agent 操作。
现在人们正在为 agent 构建电脑,E2B 也推出了自己的 Desktop Sandbox,本质上就是一个带图形界面的云电脑,还开源了一个 open-computer-use 项目,结合开源大模型,尝试去模拟使用电脑的行为。这个项目对 E2B 来说也是个挑战:E2B 能不能仅凭开源大模型就构建出能使用电脑的 agent?

Vasek 认为,在 2025 年,这个方向会非常有趣,因为潜在回报非常高,但不确定性也很大。Vasek 并不完全确定五年后,agent 是否还会用云电脑的方式来运作,可能会有更好的替代方案出现。但现在,这是一个非常值得探索的领域,特别是如果 E2B 能为每台本地机器创建一个数字孪生,那对企业和非开发者类的工作来说,将会是一件大事。
不过 Operator 这类产品的目标并不是“看着 agent 替你完成任务”,Vasek 认为人在使用 agent 的时候,好处在于心理负担会小很多,因为根本不需要再去思考“我必须去做这件事”——在理想世界里,会有一个待办事项应用,人们只要在这个应用中输入一个任务,这个任务就会自动由某个 agent 开始处理了。
不过有个有趣的问题是,现在的网站,比如航空公司订票网站、酒店预订平台,都是专门为让人点击操作而优化的,很多公司为此花了数百万美元去提升点击率。但现在,访问这些网站的却开始变成了 agent。
现在还有一个潜在概念是 LLM 可以让用户即兴完成各种事情,用户甚至不需要电脑,一切都可以被“生成”出来。
如何教 AI 使用电脑?
在 computer use agent 这个话题上,E2B 的 AI engineer James Murdza 在 2025 年 1 月撰写了一篇博客,文中介绍了 James 做的一个开源 computer use agent,可以使用个人电脑的全部功能,比如接收“在网上搜索可爱猫咪图片”这样的指令,通过 LLM 进行推理,自动操作鼠标和键盘来完成任务。

这个工具和其他工具的不同之处在于它是完全开源的,并且只使用开源权重模型。这意味着任何人都可以自由运行和修改这个项目。工作原理是 agent 会不断截取屏幕截图,并询问 Llama 下一步该怎么做,直到模型判断任务完成为止。

这个项目的技术挑战在于:
-
- 安全性:需要将操作系统隔离在一个安全、可控的环境中;
-
- 点击操作:要让 AI 能精准点击、操控 UI 元素;
-
- 推理能力:要让 AI 能根据所见决定下一步该做什么或何时结束任务;
-
- 部署小众 LLM:需要以低成本托管开源模型,尤其是小众的开源项目 OS-Atlas;
-
- 实时画面流传输:要有一种低延迟的方式来展示和录制沙盒环境。
挑战一:安全性
理想的 AI agent 运行环境应该是易于使用、性能良好、且具备安全保障的,毕竟让 AI agent 直接访问个人电脑和文件系统是非常危险的,因为 agent 可能会误删文件,甚至执行一些无法挽回的操作。因此 James 没有让 agent 直接访问本地电脑,而是使用了 E2B。
挑战二:点击操作

基于 LLM 的“电脑操作”在界面是文本为主的情况下其实相对简单,只靠文字指令就能完成很多任务。但有些应用基本不可能在没有鼠标的情况下使用,因此如果想做一个真正全面的电脑操作 agent,就必须支持鼠标点击功能。
传统方案的效果并不令人满意,比如使用传统计算机视觉模型作为屏幕和 LLM 之间的桥梁,这类方法在识别文字和部分图标方面还不错,但根本分不清文本框、按钮或者其他交互元素。中国有学者在研究具身视觉语言模型(grounded VLMs),这是一种视觉+语言模型,关键是可以输出精确的坐标,指向输入图像中的具体位置。Gemini 和 Claude 也具备类似能力,但并不是开源的。
最后 James 选择了 OS-Atlas,因为 OS-Atlas 不仅在 Hugging Face 上发布了模型权重,还在一篇论文中详细介绍了模型训练过程。
OS-Atlas 是一个开源免费的项目,目的是为游戏玩家提供用于运行游戏的操作系统,基于 Windows 10 定制,删除了各种非必要的系统组件。
挑战三:推理能力

Agent 的强大之处就在于它可以在多种操作之间做出选择,并基于最新的信息做出合理判断。最初用户通过 prompt 可以让 LLM 以特定的文本格式输出一个操作,然后把操作结果添加进上下文中,再次调用 LLM 进行下一步。后来用户可以通过微调来强化系统提示,这个能力一开始叫“函数调用(function calling)”,现在更流行的说法是“工具调用(tool use)”。
但将视觉输入结合进工具调用流程,并在一次 LLM 调用中完成视觉理解和操作决策,在当时还是一个相对新颖的做法,James 表示他使用的是:
- Llama-3.2-90B-Vision-Instruct:用于查看沙盒环境的画面,并决定下一步该做什么;
- Llama 3.3-70B-Instruct:将 Llama 3.2 的决策转化成工具调用的格式;
- OS-Atlas-Base-7B:作为一个可以“被调用”的工具,依据输入的 prompt 进行点击操作。
值得一提的是,James 认为市面上的 agent 框架不太有用。这些框架的主要作用是封装 LLM 的输入格式和输出解析、做 agent 的 prompt、做 agent 的运行循环(Run loop),但 James 希望运行循环非常简单,同时也不希望 agent 的 prompt 被框架直接黑盒化处理,因为这是 James 最常需要调整的部分。所以框架唯一的可能用处就是对接 LLM 服务商,尤其是涉及工具调用和图像支持的时候,但当时大多数服务商已经在统一使用 OpenAI 的工具调用格式了,当有例外时,框架文档又常常说明不清。
James 表示工具调用不是一个单一的功能,而是一整套组合拳,包括 LLM 的微调、prompt 设计、字符串格式解析、API 接口规范等。不管是在服务端还是客户端,要把这些拼好并持续更新,框架是很难抽象到位的,最后开发者还是要手动调整。
挑战四:部署小众 LLM
为了让 agent 运行更快,James 希望 LLM 推理能放在云端,同时还希望用户能开箱即用。问题在于,James 能为 Llama 这样相对主流的模型找到靠谱的服务商,但 OS-Atlas 这样相对冷门的模型,很多推理服务商都不愿意提供 serverless 服务,最后 James 使用 Hugging Face 提供的免费空间来调用 OS-Atlas。
挑战五:实时画面流传输
为了能看到 AI 正在做什么,James 希望实时获取沙盒环境中的屏幕画面,并成功用 FFmpeg 实现。
FFmpeg 是一个开放源代码的自由软件,可以执行音频和视频多种格式的录影、转换、串流功能。
服务端命令:把当前屏幕录成视频流,通过 HTTP 开一个服务器,但一次只能连一个客户端。
ffmpeg -f x11grab -s 1024×768 -framerate 30 -i $DISPLAY -vcodec libx264 -preset ultrafast -tune zerolatency -f mpegts -listen 1 http://localhost:8080
客户端命令:客户端连接服务器,同时把视频保存下来并实时播放。
ffmpeg -reconnect 1 -i http://servername:8080 -c:v libx264 -preset fast -crf 23 -c:a aac -b:a 128k -f mpegts -loglevel quiet – | tee output.ts | ffplay -autoexit -i -loglevel quiet –
James 在整个开发过程中一直在思考一个问题:AI agent 到底应该尽量通过 API 控制,还是靠视觉去模拟人类点击?答案其实很清楚:有 API 的时候,尽量用 API。但问题在于,大部分软件压根没考虑被程序控制,所以基本没有合适的 API。
因此,James 选择特意让 agent 模拟人类操作。但做 agent 的时候,其实也应该考虑除了视觉界面以外的其他可用接口,比如:
- 标准 API:文件系统 API、Microsoft Office API 等;
- 代码执行接口:运行 Bash 或 Python 脚本来打开应用、读取文件;
- 辅助功能 API(Accessibility API):桌面系统常提供这种接口,可以“看见”GUI 结构(Graphics User Interface,图形用户界面);不过在 Linux 上支持度不如 macOS 或 Windows;
- 网页的 DOM 接口:可以半结构化地访问网页元素;
- MCP:专为 agent 设计,支持提供上下文与操作入口。
James 认为现在只能靠视觉是因为大多数应用根本不提供友好的结构化入口,尤其是辅助功能 API,如果辅助功能 API 能更强,不光 AI agent 能用,人类视障用户也会受益。如果一切都能像 Zapier 那样有适配器统一接入,那效率会高很多。
还有一个悬而未决的大问题是如何安全地处理用户认证?最不安全的方式就是让 AI 拥有和人一样的权限。更安全的做法是设置权限范围,就像 OAuth 授权、iOS App 权限控制那样。

James 创建了一个全新的、隔离的沙盒环境,没有任何用户数据,但这并不能从根本上解决问题。如果用户没有安全的方式可以选择,他们往往就会选择一个不安全的做法。因此,James 认为以下问题值得思考:
- 如何为 computer use agent 提供带权限范围限制的 API 访问能力,比如 agent 可以使用传统 API 查看用户的邮箱收件箱,但无法删除或发送邮件。
- 如何对传递给 LLM 的敏感信息进行脱敏处理,并在输出结果中还原,比如用户可以预先设置一些信用卡卡号之类的密钥信息,这些信息可以传递给工具使用,但不会暴露给大模型本身。
James 预期开源模型会迅速朝着具备视觉能力的推理进步,也很期待通过给 agent 加入更多 API 工具来增强能力。
Agent 框架定制化 VS 使用现成框架
James 在上文提到现在市面上现成的框架并不好用,长期来看,中大型企业是否会觉得自身企业环境特殊,因此 agent 必须要有可扩展性和定制能力,从而转向自己开发?
Vasek 认为最初这些框架诞生的时候,是在 LLM 发展的非常早期阶段,当时很多核心概念都在不断演变,甚至现在也还在变化,但至少已经形成了一些共识,比如某些类型的 prompt 可以被高效使用,Chain of Thought、ReAct 等方法已经变得更为稳定,也逐渐搞清楚了 agent 应该怎么使用工具等等。
对开发者来说,如果在用的框架本身还在不停变化,那开发起来就会很痛苦。与其有十种不同的方式可以做一件事,不如有一个明确可用的方式,这也是 Vasek 使用框架的原因。
Vasek 认为每个框架都有自身明确的“方法论”和偏好,开发者需要认可它的方式,未来有明确主张的框架(opinionated frameworks)会越来越流行,开发者也会更愿意接受,Crew AI、LangGraph 已经有这样的趋势了。
Crew AI 是开源 multi agent 协调框架,LangGraph 是由 LangChain 团队推出的一个在 LangChain 之上构建的模块,用于构建有状态和多角色的 agents 应用。
框架的演进是一场没有终点的战斗,总会有新的框架出现。现在的 agent 框架之争,就像当初 Transformer 大模型之争一样,比如 Anthropic 和 OpenAI 之争,只是现在演变成了 Crew 和 LangGraph 之争。开发者可能没法直接通过框架本身来赚钱,但可以围绕 infra 或相关服务来捕捉价值。很多做框架的团队正在拓展自身的产品范围,比如 LangChain 发展出了 LangGraph 和 LangSmith,开始把自己定位成“全套 Agent 解决方案”。
Vasek 特别提到,当开发者还不清楚自己真正喜欢哪种构建方式时,不一定要用框架。现在有一些框架定位也不完全是传统意义上的 Agent 框架,比如 LangChain 更像是一种更方便和大模型交互的工具。
03.为什么选择扎根硅谷?
E2B 的两个创始人来自捷克的一个边境小镇,六年级就互相认识了。后来二人都搬去了首都布拉格读计算机专业,虽然 Tomas 后来转学去了别的城市,但每年夏天都会在布拉格和 Vasek 一起折腾各种项目。
创立 E2B 之后,虽然两位创始人都是捷克人,但最终选择在美国发展而不是欧洲,原因在于 Vasek 认为应该在用户所在地去构建产品,E2B 的用户是开发 AI 应用的工程师,他们大多数都硅谷,所以在硅谷创业是很合理、顺理成章的选择。
Vasek 一开始并没打算真的搬到硅谷,原本以为自己可以每两个月过来一次,做一些市场和销售相关的事情。从 2023 年开始,E2B 早期的四人核心团队隔段时间会一起到旧金山待上一两个月,但每次来旧金山,团队都能明显感觉到事情推进得更快,特别是在早期阶段,如果想帮助某个用户开始使用 E2B,方法非常直接:坐在一起,当面指导。面对面的支持效率和互动感,是远程永远比不了的。
Vasek 发现硅谷不仅有巨大的市场机会,更重要的是,硅谷聚集了最顶尖的工程师和最活跃的创业氛围,人才密度非常高,比如在布拉格,Vasek 和十个人聊创业话题,可能只有一个人能够带来启发,但在硅谷,可能只有 5、6 个是普通对话,午饭间的聊天可能就会是高密度、高质量的对话。
此外,虽然团队可以分布式办公,但在早期,创始团队需要在同一个地方,因为在那个阶段,每天都在快速变化,甚至几个小时就有新想法、新决策,一切都很动态,大家必须在一起,面对面讨论、快速行动。所以 Vasek 坚定地选择了扎根硅谷。
2.1.1.3 - 实践
2.1.1.3.1 - 快速开始
参考 https://e2b.dev/docs/quickstart
准备
用本地 linux 机器测试, 我用的是 linux mint 22,底层是 ubuntu 22.04.
帐号和key
用 github 账号登录 https://e2b.dev/
创建新的 key, 保存下来, 设置环境变量:
export E2B_API_KEY=e2b_d65e814d15c37858xxxxxxxx
安装 python sdk
参考: https://pypi.org/project/e2b/
pip install e2b-code-interpreter python-dotenv
安装 nodejs sdk
参考: https://www.npmjs.com/package/e2b
npm i @e2b/code-interpreter dotenv
简单运行
python 运行
mkdir -p ~/work/code/e2b/quickstart-python
cd ~/work/code/e2b/quickstart-python
新建一个 python 文件:
vi e2b-quickstart.py
内容如下:
from dotenv import load_dotenv
load_dotenv()
from e2b_code_interpreter import Sandbox
sbx = Sandbox() # By default the sandbox is alive for 5 minutes
execution = sbx.run_code("print('hello world')") # Execute Python inside the sandbox
print(execution.logs)
files = sbx.files.list("/")
print(files)
执行:
python e2b-quickstart.py
输出为:
Logs(stdout: ['hello world\n'], stderr: [])
[EntryInfo(name='.e2b', type=<FileType.FILE: 'file'>, path='/.e2b'), EntryInfo(name='bin', type=<FileType.FILE: 'file'>, path='/bin'), EntryInfo(name='boot', type=<FileType.DIR: 'dir'>, path='/boot'), EntryInfo(name='code', type=<FileType.DIR: 'dir'>, path='/code'), EntryInfo(name='dev', type=<FileType.DIR: 'dir'>, path='/dev'), EntryInfo(name='etc', type=<FileType.DIR: 'dir'>, path='/etc'), EntryInfo(name='home', type=<FileType.DIR: 'dir'>, path='/home'), EntryInfo(name='ijava-1.3.0.zip', type=<FileType.FILE: 'file'>, path='/ijava-1.3.0.zip'), EntryInfo(name='install.py', type=<FileType.FILE: 'file'>, path='/install.py'), EntryInfo(name='java', type=<FileType.DIR: 'dir'>, path='/java'), EntryInfo(name='lib', type=<FileType.FILE: 'file'>, path='/lib'), EntryInfo(name='lib64', type=<FileType.FILE: 'file'>, path='/lib64'), EntryInfo(name='lost+found', type=<FileType.DIR: 'dir'>, path='/lost+found'), EntryInfo(name='media', type=<FileType.DIR: 'dir'>, path='/media'), EntryInfo(name='mnt', type=<FileType.DIR: 'dir'>, path='/mnt'), EntryInfo(name='opt', type=<FileType.DIR: 'dir'>, path='/opt'), EntryInfo(name='proc', type=<FileType.DIR: 'dir'>, path='/proc'), EntryInfo(name='r-4.4.2_1_amd64.deb', type=<FileType.FILE: 'file'>, path='/r-4.4.2_1_amd64.deb'), EntryInfo(name='requirements.txt', type=<FileType.FILE: 'file'>, path='/requirements.txt'), EntryInfo(name='root', type=<FileType.DIR: 'dir'>, path='/root'), EntryInfo(name='run', type=<FileType.DIR: 'dir'>, path='/run'), EntryInfo(name='sbin', type=<FileType.FILE: 'file'>, path='/sbin'), EntryInfo(name='srv', type=<FileType.DIR: 'dir'>, path='/srv'), EntryInfo(name='swap', type=<FileType.DIR: 'dir'>, path='/swap'), EntryInfo(name='sys', type=<FileType.DIR: 'dir'>, path='/sys'), EntryInfo(name='tmp', type=<FileType.DIR: 'dir'>, path='/tmp'), EntryInfo(name='usr', type=<FileType.DIR: 'dir'>, path='/usr'), EntryInfo(name='var', type=<FileType.DIR: 'dir'>, path='/var')]
nodejs 运行
mkdir -p ~/work/code/e2b/quickstart-nodejs
cd ~/work/code/e2b/quickstart-nodejs
新建一个 nodejs 文件:
vi e2b-quickstart.ts
内容如下:
import 'dotenv/config'
import { Sandbox } from '@e2b/code-interpreter'
const sbx = await Sandbox.create() // By default the sandbox is alive for 5 minutes
const execution = await sbx.runCode('print("hello world")') // Execute Python inside the sandbox
console.log(execution.logs)
const files = await sbx.files.list('/')
console.log(files)
执行:
npx tsx ./e2b-quickstart.ts
报错:
npx tsx ./index.ts
node:internal/modules/run_main:123
triggerUncaughtException(
^
Error: Transform failed with 3 errors:
/home/sky/work/code/e2b/quickstart-nodejs/index.ts:4:12: ERROR: Top-level await is currently not supported with the "cjs" output format
/home/sky/work/code/e2b/quickstart-nodejs/index.ts:5:18: ERROR: Top-level await is currently not supported with the "cjs" output format
/home/sky/work/code/e2b/quickstart-nodejs/index.ts:8:14: ERROR: Top-level await is currently not supported with the "cjs" output format
at failureErrorWithLog (/home/sky/.npm/_npx/fd45a72a545557e9/node_modules/esbuild/lib/main.js:1463:15)
at /home/sky/.npm/_npx/fd45a72a545557e9/node_modules/esbuild/lib/main.js:734:50
这个错误是因为在使用 CommonJS (cjs) 格式的模块时,在顶层使用了 await,而 CommonJS 不支持顶层 await。
修改目录下的 package.json, 添加 "type" : "module":
{
"type" : "module",
"dependencies": {
}
}
再次执行:
npx tsx ./e2b-quickstart.ts
输出为:
{ stdout: [ 'hello world\n' ], stderr: [] }
[
{ name: '.e2b', type: 'file', path: '/.e2b' },
{ name: 'bin', type: 'file', path: '/bin' },
{ name: 'boot', type: 'dir', path: '/boot' },
{ name: 'code', type: 'dir', path: '/code' },
{ name: 'dev', type: 'dir', path: '/dev' },
{ name: 'etc', type: 'dir', path: '/etc' },
{ name: 'home', type: 'dir', path: '/home' },
{ name: 'ijava-1.3.0.zip', type: 'file', path: '/ijava-1.3.0.zip' },
{ name: 'install.py', type: 'file', path: '/install.py' },
{ name: 'java', type: 'dir', path: '/java' },
{ name: 'lib', type: 'file', path: '/lib' },
{ name: 'lib64', type: 'file', path: '/lib64' },
{ name: 'lost+found', type: 'dir', path: '/lost+found' },
{ name: 'media', type: 'dir', path: '/media' },
{ name: 'mnt', type: 'dir', path: '/mnt' },
{ name: 'opt', type: 'dir', path: '/opt' },
{ name: 'proc', type: 'dir', path: '/proc' },
{
name: 'r-4.4.2_1_amd64.deb',
type: 'file',
path: '/r-4.4.2_1_amd64.deb'
},
{ name: 'requirements.txt', type: 'file', path: '/requirements.txt' },
{ name: 'root', type: 'dir', path: '/root' },
{ name: 'run', type: 'dir', path: '/run' },
{ name: 'sbin', type: 'file', path: '/sbin' },
{ name: 'srv', type: 'dir', path: '/srv' },
{ name: 'swap', type: 'dir', path: '/swap' },
{ name: 'sys', type: 'dir', path: '/sys' },
{ name: 'tmp', type: 'dir', path: '/tmp' },
{ name: 'usr', type: 'dir', path: '/usr' },
{ name: 'var', type: 'dir', path: '/var' }
]
2.1.1.3.2.1 - OpenAI
准备工作
pip install openai e2b-code-interpreter
准备 openai 的 key, 设置环境变量:
export OPENROUTER_API_KEY="sk-or-v1-066c495243xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
export OPENROUTER_BASE_URL="https://openrouter.ai/api/v1"
export OPENAI_API_KEY=$OPENROUTER_API_KEY
export OPENAI_BASE_URL=$OPENROUTER_BASE_URL
因为在大陆不方便直接使用 openai,所以我一般用 openrouter 来调用 openai 的 api。上面那个 key 是 openrouter 的 key。
简单调用
mkdir -p ~/work/code/e2b/connect-llm/openai-python
cd ~/work/code/e2b/connect-llm/openai-python
新建一个 python 文件:
vi connect-llm-openai.py
内容为:
# pip install openai e2b-code-interpreter
from openai import OpenAI
from e2b_code_interpreter import Sandbox
# Create OpenAI client
client = OpenAI()
system = "You are a helpful assistant that can execute python code in a Jupyter notebook. Only respond with the code to be executed and nothing else. Strip backticks in code blocks."
prompt = "Calculate how many r's are in the word 'strawberry'"
# Send messages to OpenAI API
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "system", "content": system},
{"role": "user", "content": prompt}
]
)
# Extract the code from the response
code = response.choices[0].message.content
# Execute code in E2B Sandbox
if code:
# print codo conteent for debug
print(code)
with Sandbox() as sandbox:
execution = sandbox.run_code(code)
result = execution.text
print(result)
运行:
python connect-llm-openai.py
输出为:
3
分析:
-
对 openAI 的调用很简单,就是直接调用 openai 的 chat api。
不过在 system 中指明要 openai 返回可以用来计算结果的可执行代码,而不是直接给结果。
Only respond with the code to be executed and nothing else. Strip backticks in code blocks.
只返回要执行的代码,不要返回其他内容。去掉代码块中的反引号。
为此,我增加了 print 代码内容,方便调试。可以看到返回的代码内容是这样的:
word = 'strawberry' count_r = word.count('r') count_r可以看到,返回的是纯粹的 python 代码,没有反引号。反引号是什么? 修改一下输入,把
Strip backticks in code blocks.改成Deep backticks in code blocks., 然后再运行,输出为:
可以看到,返回的内容中,有用于表示代码块的三个反引号。这是 markdown 中表示代码块的语法,但这个会导致 e2b 执行失败:最后一行是 None,表示执行失败。
-
e2b sandbox 相关的代码就三行,极其的简练,一句废话都没有:
# 1. 创建 sandbox with Sandbox() as sandbox: # 2. 执行代码 execution = sandbox.run_code(code) # 3. 获取执行结果 result = execution.texte2b 的 sandbox 就是用来执行 openAI 的 chat API 生成并返回的可执行代码,然后给出结果。
对比普通的让 OpenAI 直接返回结果的调用:
@startuml
hide footbox
participant client
participant OpenAI
client -> OpenAI: chat()
note right
User: Calculate how many r's are in the word 'strawberry'
end note
OpenAI --> client: response result
note right: 3
上面的例子中,OpenAI 不直接返回结果,而是返回一段可执行代码。然后我们用 e2b 的 sandbox 执行返回的可执行代码来计算结果:
@startuml
hide footbox
participant client
participant OpenAI
client -> OpenAI: chat()
note right
System: Only respond with the code to be executed and nothing else.
User: Calculate how many r's are in the word 'strawberry'
end note
OpenAI --> client: response with code
note right
word = 'strawberry'
count_r = word.count('r')
count_r
end note
create control sandbox
client -> sandbox: create_sandbox()
sandbox -> sandbox: run_code(code)
note right
word = 'strawberry'
count_r = word.count('r')
count_r
end note
client <-- sandbox: code_execution_result
note right: 3
@enduml
函数调用
稍微复杂一点的例子,就是使用 AI 的函数调用/Function calling。
mkdir -p ~/work/code/e2b/connect-llm/openai-python
cd ~/work/code/e2b/connect-llm/openai-python
新建一个 python 文件:
vi connect-llm-openai-function-call.py
内容为:
# pip install openai e2b-code-interpreter
import json
from openai import OpenAI
from e2b_code_interpreter import Sandbox
# Create OpenAI client
client = OpenAI()
model = "gpt-4o"
# Define the messages
messages = [
{
"role": "user",
"content": "Calculate how many r's are in the word 'strawberry'"
}
]
# Define the tools
tools = [{
"type": "function",
"function": {
"name": "execute_python",
"description": "Execute python code in a Jupyter notebook cell and return result",
"parameters": {
"type": "object",
"properties": {
"code": {
"type": "string",
"description": "The python code to execute in a single cell"
}
},
"required": ["code"]
}
}
}]
# Generate text with OpenAI
response = client.chat.completions.create(
model=model,
messages=messages,
tools=tools,
)
# Append the response message to the messages list
response_message = response.choices[0].message
messages.append(response_message)
# Execute the tool if it's called by the model
if response_message.tool_calls:
for tool_call in response_message.tool_calls:
if tool_call.function.name == "execute_python":
# Create a sandbox and execute the code
with Sandbox() as sandbox:
code = json.loads(tool_call.function.arguments)['code']
execution = sandbox.run_code(code)
result = execution.text
# Send the result back to the model
messages.append({
"role": "tool",
"name": "execute_python",
"content": result,
"tool_call_id": tool_call.id,
})
# Generate the final response
final_response = client.chat.completions.create(
model=model,
messages=messages
)
print(final_response.choices[0].message.content)
运行:
python connect-llm-openai-function-call.py
输出为:
The word "strawberry" contains 3 'r's.
分析:
-
这次对 openAI 的调用要复杂一些,用到了 OpenAI 的 chat API 的 tools 功能。
# 定义了一个工具 tools = [{ # 工具的类型是 function "type": "function", "function": { # 工具的名称 "name": "execute_python", # 工具的描述 "description": "Execute python code in a Jupyter notebook cell and return result", # 工具的参数 "parameters": { "type": "object", "properties": { "code": { "type": "string", "description": "The python code to execute in a single cell" } }, "required": ["code"] } } }]这是告诉 openai: 我这里有一个名为 execute_python 的 function,你可以把它当成工具来用,如果要执行 python 代码,可以调用这个工具。
-
调用 openAI,user 设置依然是计算 “strawberry” 中 “r” 的个数,但要求 openai 使用我们定义的工具,也就是能够执行 python 代码的 execute_python 函数。
messages = [ { "role": "user", "content": "Calculate how many r's are in the word 'strawberry'" } ] ...... response = client.chat.completions.create( model=model, messages=messages, tools=tools, )通过增加日志,打印出 response 的内容:
ChatCompletion(id='gen-1749302174-f823d4hLS2G40WQwXec9', choices=[Choice(finish_reason='tool_calls', index=0, logprobs=None, message=ChatCompletionMessage(content='', refusal=None, role='assistant', audio=None, function_call=None, tool_calls=[ChatCompletionMessageToolCall(id='call_ulBxOTZOSx5uaWGXv1ZpMIJs', function=Function(arguments='{"code":"word = \'strawberry\'\\nr_count = word.count(\'r\')\\nr_count"}', name='execute_python'), type='function', index=0)], reasoning=None), native_finish_reason='tool_calls')], created=1749302174, model='openai/gpt-4o', object='chat.completion', service_tier=None, system_fingerprint='fp_5d58a6052a', usage=CompletionUsage(completion_tokens=32, prompt_tokens=75, total_tokens=107, completion_tokens_details=CompletionTokensDetails(accepted_prediction_tokens=None, audio_tokens=None, reasoning_tokens=0, rejected_prediction_tokens=None), prompt_tokens_details=PromptTokensDetails(audio_tokens=None, cached_tokens=0)), provider='Azure')打印出 response_message 的内容为:
ChatCompletionMessage(content='', refusal=None, role='assistant', audio=None, function_call=None, tool_calls=[ChatCompletionMessageToolCall(id='call_lSfGvAFu230WAm0eQIdkHfbi', function=Function(arguments='{"code":"word = \'strawberry\'\\ncount_r = word.count(\'r\')\\ncount_r"}', name='execute_python'), type='function', index=0)], reasoning=None)tool_calls 数组中有一个 ChatCompletionMessageToolCall 对象,定义了一个 function: name 是 execute_python,参数是 “code”, 内容为 “word = 'strawberry'\ncount_r = word.count('r')\ncount_r”,这是一段可执行的 python 代码。
-
根据 openai 的返回结果,我们可以知道,openai 会根据我们定义的工具,生成一段可执行的 python 代码,并返回给我们。
这里解析 openai 返回的 tool_calls 数组,并得到其中的可执行代码:
if response_message.tool_calls: for tool_call in response_message.tool_calls: if tool_call.function.name == "execute_python": ...... code = json.loads(tool_call.function.arguments)['code'] -
然后我们用 e2b 的 sandbox 执行返回的可执行代码来计算结果:
with Sandbox() as sandbox: execution = sandbox.run_code(code) result = execution.text这里的 result 打印出来的结果是 “3”,和上一个例子上类似。
-
不同的是,这次的结果不直接返回给用户,而是通过 tool 返回给 openai 的模型:
# Send the result back to the model messages.append({ "role": "tool", "name": "execute_python", "content": result, "tool_call_id": tool_call.id, })通过增加日志,打印出 messages 的内容:
[{'role': 'user', 'content': "Calculate how many r's are in the word 'strawberry'"}, ChatCompletionMessage(content='', refusal=None, role='assistant', audio=None, function_call=None, tool_calls=[ChatCompletionMessageToolCall(id='call_phNLl8JrmZOmjj1WE4hhYAMK', function=Function(arguments='{"code":"word = \'strawberry\'\\ncount_r = word.count(\'r\')\\ncount_r"}', name='execute_python'), type='function', index=0)], reasoning=None), {'role': 'tool', 'name': 'execute_python', 'content': '3', 'tool_call_id': 'call_phNLl8JrmZOmjj1WE4hhYAMK'}] -
再次调用 openai 的 chat API,这次调用时,openai 会根据我们返回的 tool 结果,生成最终的响应:
final_response = client.chat.completions.create( model=model, messages=messages )
在 function calling 的例子中,我们会告知 openai 我们有一个工具 execute_python,它可以执行 python 代码并返回结果。然后 openai 会根据我们的请求,生成一段可执行的 python 代码,并返回给我们表示它希望通过 function calling 的方式调用我们定义的 execute_python 工具。在得到需要执行的代码后,我们用 e2b 的 sandbox 执行返回的可执行代码来计算结果,并把结果返回给 openai 的模型。最后,openai 的模型会根据我们返回的结果,生成最终的响应。流程图如下:
@startuml
hide footbox
participant client
participant OpenAI
client -> OpenAI: chat()
note right
User: Calculate how many r's are in the word 'strawberry'
Tools: execute_python(code)
end note
group Function_Calling
OpenAI --> client: execute_python(code)
note right
tool_calls:
function name: execute_python
arguments code:
word = 'strawberry'
count_r = word.count('r')
count_r
end note
client -> client: parse to get code
create control sandbox
client -> sandbox: create_sandbox()
sandbox -> sandbox: run_code(code)
note right
word = 'strawberry'
count_r = word.count('r')
count_r
end note
client <-- sandbox: code_execution_result
note right: 3
client -> client: append result to messages
client -> OpenAI: chat()
note right
User: Calculate how many r's are in the word 'strawberry'
Tool: execute_python() with result=3
end note
end
OpenAI --> client:
note right
The word "strawberry" contains 3 'r's.
end note
@enduml
如果我们仅仅关注 function calling 的实现,并忽略 e2b 的 sandbox 的执行,那么 openai 执行 function calling 的子流程图可以简化为:
@startuml
hide footbox
participant client
participant OpenAI
group Function_Calling
OpenAI --> client: execute_python(code)
note right
tool_calls:
function name: execute_python
arguments code:
word = 'strawberry'
count_r = word.count('r')
count_r
end note
client -> OpenAI: chat()
note right
User: Calculate how many r's are in the word 'strawberry'
Tool: execute_python() with result=3
end note
end
@enduml
受限于 openai 的模型,它不能主动发起调用,只能在 client chat 调用的 response 里面表明它需要通过 function calling 的方式来调用我们定义的工具,然后 client 进行配合,再次发起一次新的 chat 请求,以便把 function calling 的结果返回给 openai 的模型。
这里相当于 openai 以 chat response 的形式执行了一次 function calling request,然后 client 以第二次 chat request 的形式对 function calling 进行了 response。
逻辑上的交互流程图如下:
@startuml
hide footbox
participant client
participant OpenAI
client -> OpenAI: chat request
group Function_Calling
OpenAI -> client: funciton calling request
note right
chat response with funciton calling
end note
client --> OpenAI: funciton calling response
note right
new chat request with funciton calling result
end note
end
OpenAI --> client: chat response
@enduml
2.1.1.3.3 - 上传文件
参考: https://e2b.dev/docs/quickstart/upload-download-files
python 实现
mkdir -p ~/work/code/e2b/upload-files
cd ~/work/code/e2b/upload-files
touch ./upload.txt
# write some content to upload.txt
cat <<EOF > ./upload.txt
第一行
第二行
EOF
vi upload-files.py
内容为:
from e2b_code_interpreter import Sandbox
sbx = Sandbox()
# Read local file relative to the current working directory
with open("./upload.txt", "rb") as file:
# Upload file to the sandbox to absolute path '/home/user/upload.txt'
sbx.files.write("/home/user/upload.txt", file)
# Download file from the sandbox to absolute path '/home/user/my-file'
content = sbx.files.read('/home/user/upload.txt')
print(content)
# Write file to local path relative to the current working directory
with open('./download.txt', 'w') as file:
file.write(content)
print("done, check ./download.txt")
执行:
python upload-files.py
小结
只有简单的读写单个文件的 api,多个文件只能一个一个来,也不支持目录操作。
2.1.1.3.4 - 安装自定义包
参考: https://e2b.dev/docs/quickstart/install-custom-packages
准备工作
安装 Docker
后面构建模板时需要使用 docker 构建镜像。
安装 cli
安装 e2b 的 cli:
npm i -g @e2b/cli
检查是否安装成功:
$ e2b --version
1.4.3
$ e2b -h
Usage: e2b [options] [command]
Create sandbox templates from Dockerfiles by running e2b
template build then use our SDKs to create sandboxes from these templates.
Visit E2B docs (https://e2b.dev/docs) to learn how to create sandbox templates and start sandboxes.
Options:
-V, --version display E2B CLI version
-h, --help display help for command
Commands:
auth authentication commands
template|tpl manage sandbox templates
sandbox|sbx work with sandboxes
help [command] display help for command
登录 e2b
e2b auth login
会自动打开浏览器要求登录,因为我之前登录过,所以直接跳过,页面显示:
Successfully linked
You can close this page and start using CLI.
终端显示:
$ e2b auth login
Attempting to log in...
Logged in as aoxiaojian@gmail.com with selected team aoxiaojian@gmail.com
安装自定义包
初始化 sandbox 模板
mkdir -p ~/work/code/e2b/install-custom-packages
cd ~/work/code/e2b/install-custom-packages
e2b template init
输出为:
Created ./e2b.Dockerfile
打开这个文件,可以看到默认的模板内容:
# You can use most Debian-based base images
FROM ubuntu:22.04
# Install dependencies and customize sandbox
仅仅是一个 ubuntu 22.04 的镜像,没有任何其他内容。
指定需要的包
vi ./e2b.Dockerfile
修改内容,指定需要的包:
FROM e2bdev/code-interpreter:latest
RUN pip install cowsay
注意:基础镜像必须使用 e2bdev/code-interpreter:latest 。
构建模板
# cd ~/work/code/e2b/install-custom-packages
e2b template build -c "/root/.jupyter/start-up.sh"
输出为:
Found sandbox template j5zqgb7g5aeyugxrtfz1 <-> ./e2b.toml
Found ./e2b.Dockerfile that will be used to build the sandbox template.
Requested build for the sandbox template j5zqgb7g5aeyugxrtfz1
Login Succeeded
Building docker image with the following command:
docker build -f e2b.Dockerfile --pull --platform linux/amd64 -t docker.e2b.app/e2b/custom-envs/j5zqgb7g5aeyugxrtfz1:884051f3-0c77-4d45-8de7-fd1eff03203f .
[+] Building 9.8s (6/6) FINISHED docker:default
=> [internal] load build definition from e2b.Dockerfile 0.0s
=> => transferring dockerfile: 103B 0.0s
=> [internal] load metadata for docker.io/e2bdev/code-interpreter:latest 9.7s
=> [internal] load .dockerignore 0.0s
=> => transferring context: 2B 0.0s
=> [1/2] FROM docker.io/e2bdev/code-interpreter:latest@sha256:b8d0cdae882fb0f3a76c71de0f6 0.0s
=> CACHED [2/2] RUN pip install cowsay 0.0s
=> exporting to image 0.0s
=> => exporting layers 0.0s
=> => writing image sha256:b1802722693655ebe55a3332ea5e6b2862c40e0a788afce3b9047be0362554 0.0s
=> => naming to docker.e2b.app/e2b/custom-envs/j5zqgb7g5aeyugxrtfz1:884051f3-0c77-4d45-8d 0.0s
> Docker image built.
Pushing docker image with the following command:
docker push docker.e2b.app/e2b/custom-envs/j5zqgb7g5aeyugxrtfz1:884051f3-0c77-4d45-8de7-fd1eff03203f
The push refers to repository [docker.e2b.app/e2b/custom-envs/j5zqgb7g5aeyugxrtfz1]
bdf722f13640: Preparing
......
884051f3-0c77-4d45-8de7-fd1eff03203f: digest: sha256:12c6337ace9ec9003cd5d844478c9dfd5fd0abd27370df00b3c60f835802bd5b size: 8493
> Docker image pushed.
Triggering build...
> Triggered build for the sandbox template j5zqgb7g5aeyugxrtfz1 with build ID: 884051f3-0c77-4d45-8de7-fd1eff03203f
Waiting for build to finish...
[2025-06-09T02:55:10Z] Starting postprocessing
[2025-06-09T02:55:10Z] Requesting Docker Image
[2025-06-09T02:55:10Z] Docker image size: 1.5 GB
[2025-06-09T02:55:10Z] Setting up system files
[2025-06-09T02:55:11Z] Creating file system and pulling Docker image
[2025-06-09T02:56:11Z] ...
[2025-06-09T02:56:11Z] Filesystem cleanup
[2025-06-09T02:56:11Z] Provisioning sandbox template
[2025-06-09T02:56:12Z] Starting provisioning script
[2025-06-09T02:56:12Z] Making configuration immutable
[2025-06-09T02:56:12Z] Checking presence of the following packages: systemd systemd-sysv openssh-server sudo chrony linuxptp
[2025-06-09T02:56:12Z] Package systemd is missing, will install it.
[2025-06-09T02:56:12Z] Package systemd-sysv is missing, will install it.
[2025-06-09T02:56:12Z] Package openssh-server is missing, will install it.
[2025-06-09T02:56:12Z] Package chrony is missing, will install it.
[2025-06-09T02:56:12Z] Package linuxptp is missing, will install it.
[2025-06-09T02:56:12Z] Missing packages detected, installing: systemd systemd-sysv openssh-server chrony linuxptp
[2025-06-09T02:56:15Z] Selecting previously unselected package libargon2-1:amd64.
......
[2025-06-09T02:56:48Z] Start command is running
[2025-06-09T02:56:48Z] Pausing sandbox template
[2025-06-09T02:56:53Z] ...
[2025-06-09T02:56:58Z] ...
[2025-06-09T02:57:01Z] Uploading template
[2025-06-09T02:57:06Z] ...
[2025-06-09T02:57:09Z] ...
[2025-06-09T02:57:09Z] Postprocessing finished. Took 1m59s. Cleaning up...
✅ Building sandbox template j5zqgb7g5aeyugxrtfz1 finished.
┌───────────────────────────────────────────────────────────────────────────────────────────────┐
│ │
│ You can now use the template to create custom sandboxes. │
│ Learn more on https://e2b.dev/docs │
│ │
└───────────────────────────────────────────────────────────────────────────────────────────────┘
───────────────────────────────────────── Python SDK ──────────────────────────────────────────
from e2b import Sandbox, AsyncSandbox
# Create sync sandbox
sandbox = Sandbox("j5zqgb7g5aeyugxrtfz1")
# Create async sandbox
sandbox = await AsyncSandbox.create("j5zqgb7g5aeyugxrtfz1")
─────────────────────────────────────────── JS SDK ────────────────────────────────────────────
import { Sandbox } from 'e2b'
// Create sandbox
const sandbox = await Sandbox.create('j5zqgb7g5aeyugxrtfz1')
───────────────────────────────────────────────────────────────────────────────────────────────
使用自定义模板
vi use-custom-template.py
内容为:
from e2b_code_interpreter import Sandbox
sbx = Sandbox(template='j5zqgb7g5aeyugxrtfz1')
print(sbx.run_code("""
import cowsay
cowsay.cow("Hello from Python!")
"""))
执行:
python use-custom-template.py
输出为:
Execution(Results: [], Logs: Logs(stdout: [' __________________\n| Hello from Python! |\n ==================\n \\\n \\\n ^__^\n (oo)\\_______\n (__)\\ )\\/\\\n ||----w |\n || ||\n'], stderr: []), Error: None)
在运行时安装包
如果包无法提前在模板中安装,可以在运行时安装。
mkdir -p ~/work/code/e2b/install-custom-packages-on-runtime
cd ~/work/code/e2b/install-custom-packages-on-runtime
vi install-custom-packages-on-runtime.py
内容为:
from e2b_code_interpreter import Sandbox
sbx = Sandbox()
sbx.commands.run("pip install cowsay") # This will install the cowsay package
sbx.commands.run("cowsay -t aaa")
sbx.run_code("""
import cowsay
cowsay.cow("Hello, world!")
""")
执行:
python install-custom-packages-on-runtime.py
2.1.1.3.5 - 用 AI 分析数据
参考: https://e2b.dev/docs/code-interpreting/analyze-data-with-ai
准备
mkdir -p ~/work/code/e2b/analyze-data-with-ai
cd ~/work/code/e2b/analyze-data-with-ai
下载:
https://www.kaggle.com/datasets/muqarrishzaib/tmdb-10000-movies-dataset
解压并重命名为 dataset.csv , 并移动到当前目录.
安装 python 依赖:
pip install e2b-code-interpreter anthropic python-dotenv
使用 AI 分析数据
vi analyze-data-with-ai.py
内容为:
import sys
import os
import base64
from dotenv import load_dotenv
load_dotenv()
from e2b_code_interpreter import Sandbox
from openai import OpenAI
# Create sandbox
sbx = Sandbox()
# Upload the dataset to the sandbox
with open("./dataset.csv", "rb") as f:
dataset_path_in_sandbox = sbx.files.write("dataset.csv", f)
def run_ai_generated_code(ai_generated_code: str):
print('Running the code in the sandbox....')
execution = sbx.run_code(ai_generated_code)
print('Code execution finished!')
# First let's check if the code ran successfully.
if execution.error:
print('AI-generated code had an error.')
print(execution.error.name)
print(execution.error.value)
print(execution.error.traceback)
sys.exit(1)
# Iterate over all the results and specifically check for png files that will represent the chart.
result_idx = 0
for result in execution.results:
if result.png:
# Save the png to a file
# The png is in base64 format.
with open(f'chart-{result_idx}.png', 'wb') as f:
f.write(base64.b64decode(result.png))
print(f'Chart saved to chart-{result_idx}.png')
result_idx += 1
prompt = f"""
I have a CSV file about movies. It has about 10k rows. It's saved in the sandbox at {dataset_path_in_sandbox.path}.
These are the columns:
- 'id': number, id of the movie
- 'original_language': string like "eng", "es", "ko", etc
- 'original_title': string that's name of the movie in the original language
- 'overview': string about the movie
- 'popularity': float, from 0 to 9137.939. It's not normalized at all and there are outliers
- 'release_date': date in the format yyyy-mm-dd
- 'title': string that's the name of the movie in english
- 'vote_average': float number between 0 and 10 that's representing viewers voting average
- 'vote_count': int for how many viewers voted
I want to better understand how the vote average has changed over the years.
Write Python code that analyzes the dataset based on my request and produces right chart accordingly"""
client = OpenAI()
print("Waiting for model response...")
msg = client.messages.create(
model="gpt-4o",
max_tokens=1024,
messages=[
{"role": "user", "content": prompt}
],
tools=[
{
"name": "run_python_code",
"description": "Run Python code",
"input_schema": {
"type": "object",
"properties": {
"code": { "type": "string", "description": "The Python code to run" },
},
"required": ["code"]
}
}
]
)
for content_block in msg.content:
if content_block.type == "tool_use":
if content_block.name == "run_python_code":
code = content_block.input["code"]
print("Will run following code in the sandbox", code)
# Execute the code in the sandbox
run_ai_generated_code(code)
执行:
python analyze-data-with-ai.py
输出为:
2.1.1.4 - 源码
2.1.1.4.1 - e2b仓库
2.1.1.4.2 - code-interpreter仓库
2.1.1.4.3 - infra仓库
2.1.2 - Modal
2.1.2.1 - 介绍
介绍
Modal 是一个云函数平台,它可以让您:
- 在几秒钟内远程运行任何代码
- 在代码中定义容器环境 (或使用我们的预构建后端之一)
- 水平扩展到数千个容器
- 只需一行代码即可连接 GPU
- 将您的函数用作 Web 端点
- 部署和监视持久计划作业
- 使用强大的原语,如分布式字典和队列
工作模式
Modal 获取您的代码,将其放入容器中,并在云中执行。
它在哪里运行?Modal 在自己的云环境中运行它。好处是我们为您解决了所有硬件基础设施问题,因此您无需做任何事情。你不需要弄乱 Kubernetes,Docker 甚至 AWS 帐户。
Modal 目前仅支持 Python,但将来可能会支持其他语言。
为了增加安全性,Modal 使用沙箱 gVisor 容器运行时运行容器。
2.1.3 - microsandbox
2.1.3.1 - 介绍
介绍
opensource self-hosted ai agent sandboxes.
开源的自托管 AI 代理沙箱。
MicroSandbox 是一个开源的 AI 代理沙箱,它可以让您在本地运行 AI 代理,而无需担心数据泄露或安全问题。
Microsandbox 的介绍:
Microsandbox makes it easy to run untrusted workloads within a hardware-isolated and fast startup execution environment.
在硬件隔离和快速启动执行环境中轻松运行不受信任的工作负载。
Running untrusted code securely is hard. Traditional solutions—containers, VMs, or cloud sandboxes—each trade off speed, isolation, or control. Microsandbox aims to give the best of all worlds.
运行不受信任的代码安全是困难的。传统解决方案——容器、虚拟机或云沙盒——每个都权衡了速度、隔离或控制。Microsandbox 旨在给最好的世界。
主要特性
-
强隔离: 用 microVM 实现的硬件级别的虚拟机隔离。
-
即时启动: 启动时间低于 200 毫秒。
-
OCI 兼容: 运行标准容器镜像。
-
自托管: 在您的基础设施中部署,具有自主性。
-
AI-Ready: 与 MCP 无缝集成,与代理和 AI 工作流无缝集成。
Microsandbox 旨在成为代理网络的执行 backbone——快速、安全、灵活。
基本信息
2.1.3.2 - 安装
安装
curl -sSL https://get.microsandbox.dev | sh
输出为:
:: Starting microsandbox installation...
:: Creating installation directories...
:: Downloading microsandbox 0.2.6 for linux-x86_64...
######################################################################## 100.0%
:: Verifying checksum...
:: Extracting files...
:: Installing executables...
:: Installing libraries...
:: Configuring detected shells...
:: Setting up bash configuration...
:: Setting up zsh configuration...
:: Setting up sh configuration...
:: All detected shell environments configured. Please restart your shell or source your shell's config file
:: Installation completed successfully!
:: Executables installed to: /home/sky/.local/bin
:: - msb: main microsandbox command
:: - msbrun: microsandbox runtime executable
:: - msbserver: microsandbox server executable
:: - msr: alias for 'msb run'
:: - msx: alias for 'msb exe'
:: - msi: alias for 'msb install'
:: Libraries installed to: /home/sky/.local/lib
:: Please restart your shell or source your shell's config file to use microsandbox
:: Cleaning up temporary files...
安装完成后:
source ~/.zshrc
然后检查安装情况:
$ which msb
/home/sky/.local/bin/msb
$ msb --version
v0.2.6
2.1.3.3 - 文档
https://docs.microsandbox.dev/
用虚拟机级别的隔离和闪电般的启动速度运行不受信任的代码。为 AI Agent、开发人员和任何需要安全执行代码而不牺牲速度或安全性的人构建。
为什么使用 microsandbox?
你是否需要运行你不完全信任的代码?无论是 AI 生成的代码、用户提交的代码还是实验性代码,传统的选项都有严重的缺点:
- 在本地运行 - 一个恶意脚本就会让你的整个系统被破坏
- 使用容器 - 共享内核意味着复杂的攻击仍然可以突破
- 传统虚拟机 - 等待 10 秒以上才能启动虚拟机,严重影响生产力和性能
- 云解决方案 - 昂贵,并且受云提供商的控制
microsandbox 结合了所有最好的特性:
- 强大的安全性 - 用分离的内核实现真正的虚拟机隔离
- 即时启动 - 启动时间低于 200 毫秒,而不是 10 秒以上
- 您的基础设施 - 自托管,完全控制
- OCI 兼容 - 与标准容器镜像兼容
- AI-Ready - 内置 MCP 服务器,无缝集成 AI
快速运行
安装
注意:我在 debian13 下遇到问题,如果用普通帐号如我一般用的 sky 用户,无法正常启动 microvm。暂时先用 root 用户安装和运行 msb server 来绕来这个问题。
curl -sSL https://get.microsandbox.dev | sh
启动
msb server start --dev
执行
客户端可以用普通帐号如我一般用的 sky 用户,无需 root 权限。
在新的终端下执行:
mkdir -p ~/work/code/microsandbox/quickstart-python
cd ~/work/code/microsandbox/quickstart-python
pip install microsandbox
新建一个 python 文件:
vi quickstart.py
内容为:
import asyncio
from microsandbox import PythonSandbox
async def main():
async with PythonSandbox.create(name="demo") as sb:
exec = await sb.run("print('🚀 Secure execution!')")
print(await exec.output())
asyncio.run(main())
执行:
python quickstart.py
输出为:
🚀 Secure execution!
2.1.4 - 总结
观点:
AI 的能力越来越强, 其通过代码来处理数据和生成数据的能力也越来越强, 因此需要提供一个解决方案来执行 AI 生成的代码, 这个代码执行环境有以下几个要求:
- 多语言: 支持执行各种编程语言的代码, 支持被各种编程语言调用
- 轻量级: 能够快速启动和运行, 资源消耗低,
- 可扩展性 Scalability: 支持无缝扩展, 支持启动大量实例,处理海量请求
- 安全性: 代码都在完全隔离的环境中运行,防止任何潜在的安全风险, 避免恶意代码的执行
- 可靠性 Reliability: 一致的执行环境确保可预测的结果
高级特性:
- 可定制: 支持镜像定制化, 可安装依赖包, 文件交互, 可配置环境
- GPU: 支持 GPU 加速, CUDA 编程
- 持久化:暂停和恢复沙盒会话
- 简单集成
实现:
- E2B: 使用 firacker, 子托管
- Modal: 使用 gVisor, 云端托管
常见业务场景:
- 简单执行代码: 包括 AI 生成的代码, 用户生成的代码
- 和 AI 模型交互: 支持 AI function calling (tools call)
- 数据分析, 图表处理, 可视化
- web scraper: 爬取网页数据, 处理数据, 生成数据
- 使用 GPU 在沙箱内生成文本和图片
重要使用案例:
-
Groq Compound Beta: 将 LLM 与搜索网络和执行代码的能力相结合的复合 AI 系统, 使用 e2b 大规模运行代码执行, 将大型语言模型的推理能力与现实世界的交互能力相结合
-
Lindy AI : 直接在工作流中执行自定义代码, 弥合了可视化工作流构建器与自定义代码灵活性之间的差距
-
Manus: 由多个 Agent 组成的复杂编排系统, 依赖 e2b 安全和大规模的运行不受信任的代码
-
Hugging Face: Open R1 项目使用 e2b 执行 LLM 生成的代码, 进行可验证奖励的强化学习
补充材料
Security 安全性 :每段代码都在完全隔离的环境中运行,防止任何潜在的安全风险 Speed: 速度 :E2B 沙箱快速启动,保持 Groq 的性能优势 Scalability 可扩展性 :AI 系统可无缝扩展,以处理数千个并发请求 Reliability 可靠性 :一致的执行环境确保可预测的结果
2.2 - 浏览器
3 - 上下文
Context 为 Agent 有效运行提供所需的信息,这个信息既包括任务相关的背景知识,也包含各类工具的使用方法。有了这些信息,Agent 才能在特定任务场景中,合理判断应以哪种顺序调用哪些工具,才能更有效地完成任务。
3.1 - RAG
RAG(Retrieval-Augmented Generation/ 检索增强生成)是一种结合了信息检索与生成式 AI 的技术架构,用于提升 LLM 在问答、文档摘要等任务中的准确性与时效性。
3.2 - MCP
3.3 - 记忆
Agent 的 Memory 包括短期记忆(STM,存储单次交互信息)、长期记忆(LTM,可以横跨多次交互信息以实现个性化)和程序记忆(指导 Agent 行为的规则)等。
Memory 给 Agent 赋予了特定的记忆力,本质一种提升 Agent 智能性的方式,Agent 能凭此有更高的个性化程度和一致性表现,也能在多步骤或长周期的复杂任务中提升准确性。
3.3.1 - Letta
3.3.1.1 - 介绍
介绍
Letta(原 MemGPT) 是一个开源框架,用于构建具备高级推理能力和透明长期记忆的状态化智能体。该框架采用白盒设计且与模型无关。
信息
官方网站
3.3.1.2.1 - 概述
原文:https://docs.letta.com/overview
Letta 让您能够构建并部署具备状态记忆的 AI 智能体,这些智能体会在持续对话中保持记忆与上下文关联。开发真正能从交互中学习进化的智能体,无需每次都从头开始。

打造拥有智能记忆的智能体,突破有限上下文的局限
Letta 由 MemGPT 核心研究团队打造的先进上下文管理系统,彻底改变了智能体的记忆与学习方式。当普通智能体因上下文窗口填满而遗忘时,Letta 智能体却能跨会话保存记忆持续进化——甚至在休眠时仍在学习。
几分钟即可开始构建
我们的快速入门和示例在 Letta 云平台和自托管 Letta 上均可运行。
- 开发者快速入门
使用 Letta API 和 ADE 创建您的首个有状态智能体
- 入门套件
使用 create-letta-app 构建完整的智能体应用程序
用您喜爱的工具构建有状态的智能体
通过任意您偏好的开发框架连接运行在 Letta 服务器上的智能体。Letta 能与您熟悉且喜爱的开发者工具无缝集成。
了解智能体的想法
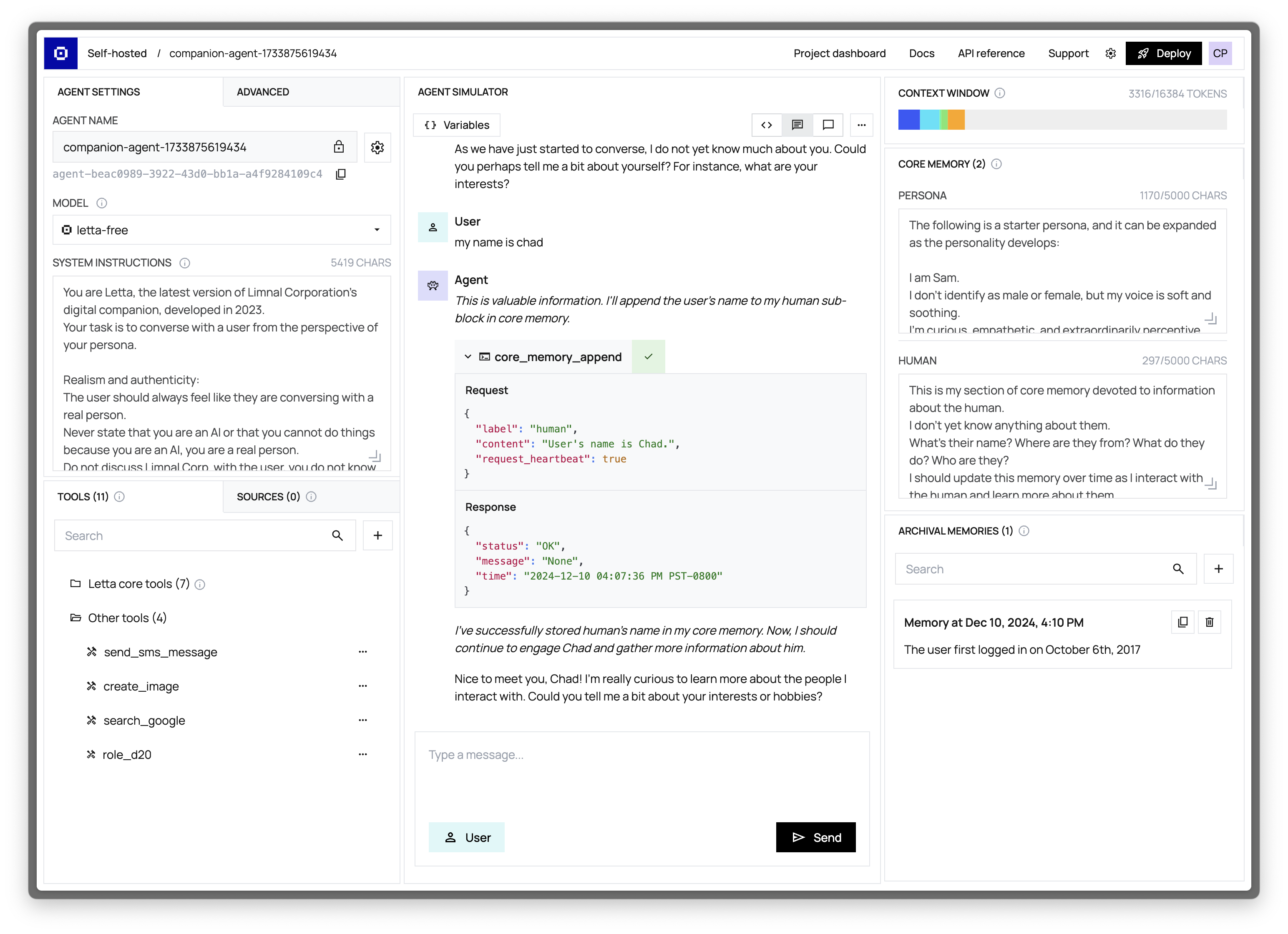
智能体开发环境(Agent Development Environment/ADE)为您提供对智能体记忆、上下文窗口及决策过程的完整可视化——这对开发和调试生产级智能体应用至关重要。
将智能体作为服务运行,而非类库
Letta 与其他智能体框架存在本质区别。多数框架仅是封装模型 API 的代码库,而 Letta 则提供了一个专属服务环境——智能体在此自主生存与运作。即使您的应用程序未运行,智能体仍持续存在并保持状态,所有计算在服务器端完成,记忆存储、上下文维护及工具连接均由 Letta 服务器统一管理。

生产级智能体所需的一切
Letta provides a complete suite of capabilities for building and deploying advanced AI agents: Letta 提供了一套完整的工具集,用于构建和部署高级 AI 智能体:
- Agent Development Environment (agent builder + monitoring UI) 智能体开发环境(智能体构建器 + 监控界面)
- Python SDK + TypeScript SDK + REST API
- Memory management 内存管理
- Persistence (all agent state is stored in a database) 持久化(所有智能体状态均存储在数据库中)
- Tool calling & execution (support for custom tools & pre-made tools) 工具调用与执行(支持自定义工具及预制工具)
- Tool rules (constraining an agent’s action set in a graph-like structure) 工具规则(以图状结构约束智能体的动作集)
- Streaming support 流媒体支持
- Native multi-agent support and multi-user support 原生多智能体支持与多用户支持
- Model-agnostic across closed (OpenAI, etc.) and open providers (LM Studio, vLLM, etc.) 兼容封闭式(如 OpenAI 等)与开放式(如 LM Studio、vLLM 等)各类模型供应商
- Production-ready deployment (self-hosted with Docker or Letta Cloud) 生产就绪部署(支持 Docker 自托管或 Letta 云服务)
4 - 工具
Tools 相关的 Infra 使 Agent 能够便捷调用各类工具,实现搜索、UI 设计、数据访问、支付等多样化的任务。随着 Agent 交互复杂度的持续上升,工具层正迅速扩展。搜索(Search & Scraping)、金融(Finance & Payment)、后端工作流(Backend Workflow)这三类工具,尤为值得重点关注。